Adding some more functionality to merge the test data with the New York City Zip data to provide more details about each location where the tested people are from .
import datetime
import json
import requests
import os
import re
import sys
RAW_ZCTA_DATA_LINK = 'https://raw.githubusercontent.com/nychealth/coronavirus-data/master/tests-by-zcta.csv'
ALL_ZCTA_DATA_CSV = 'all_zcta_data.csv'
BIN_DIR = os.path.abspath(os.path.dirname(__file__))
DB_DIR = os.path.join(BIN_DIR, '..', 'db')
NA_ZIP = "88888"
THIS_SCRIPT = sys.argv[0]
ZIP_DB = os.path.join(DB_DIR, 'zip_db.json')
...
...
def get_zip_data():
z_db = open(ZIP_DB, 'r')
zip_data = json.load(z_db)
z_db.close()
return zip_data
def get_filler_location_rec(bad_zip=NA_ZIP):
label = 'Unknown-' + bad_zip
return {
'zip': bad_zip,
'borough': label,
'city': label,
'district': label,
'county': label
}
# Zip: 11697
# Data: {"borough": "Queens", "city": "Breezy Point", "county": "Queens", "district": "Rockaways"}
# {
# "zip": "11697",
# "positive": "82",
# "total_tested": "193",
# "cumulative_percent_of_those_tested": "42.49"
# }
def merge_zip_data():
all_zip_data = get_zip_data()
todays_test_data = get_todays_test_data()
merged_data = []
for td in todays_test_data:
if td['zip'] == 'MODZCTA':
continue
zip_data = all_zip_data.get(td['zip'])
if not zip_data:
print("NO Zip data for " + td['zip'])
zip_data = get_filler_location_rec(td['zip'])
zip_data.update(td.copy())
merged_data.append(zip_data)
return merged_data
def sort_test_data_func(zip_data):
return int(zip_data['positive'])
def write_todays_data_to_csv():
merged_test_data = merge_zip_data()
csv_file = get_todays_csv_file()
col_headers = [
'Zip',
'Date',
'City',
'District',
'Borough',
'Total Tested',
'Positive',
'% of Tested']
cols = [
'zip',
'yyyymmdd',
'city',
'district',
'borough',
'total_tested',
'positive',
'cumulative_percent_of_those_tested']
merged_test_data_sorted = sorted( merged_test_data, key=sort_test_data_func, reverse=True)
# merged_test_data_sorted = merged_test_data
csv_fh = open(csv_file, 'w')
csvwriter = csv.DictWriter(csv_fh, fieldnames=cols, restval='')
csvwriter.writeheader()
for zip_test_data in merged_test_data_sorted:
ztd = {x: zip_test_data[x] for x in cols}
csvwriter.writerow(ztd)
csv_fh.close()
print("Finished writing to the " + csv_file)
The first subroutine, 'get_zip_data' just reads in the ZipCode data using Pythons 'json' library. The data comes in this format:
[
{
"zip": "88888",
"yyyymmdd": "20200504",
"positive": "1607",
"total_tested": "1917",
"cumulative_percent_of_those_tested": "83.83"
},
{
"zip": "10001",
"yyyymmdd": "20200504",
"positive": "311",
"total_tested": "878",
"cumulative_percent_of_those_tested": "35.42"
},
...The ‘get_filler_location_rec’ function adds default data in the case where sometimes the NYC department of health doesn’t provide the ZipCode for the test set.
The test data and the ZipCode information is then merged to add more locations details to the test results. It loops through the test data results, and for each record it does this,
zip_data = all_zip_data.get(td['zip'])
...
zip_data.update(td.copy())It gets a dictionary of the location information for the zip code, updates that with a copy of the test data for that location. The combined Dictionary is then appended to the list of merged test data.
merged_data.append(zip_data)Writing out the merged data to a CSV file can be done using the csv library. Id like to sort it in order of the number of positive cases descending, using the ‘sorted’ function and applying my sort criteria with
def sort_test_data_func(zip_data):
return int(zip_data['positive'])
...
...
merged_test_data_sorted = sorted( merged_test_data, key=sort_test_data_func, reverse=True)The resulting CSV file was double spaced. So, after looking at the ‘csv’ library docs I changed the file open statement from:
csv_fh = open(csv_file, 'w')to
csv_fh = open(csv_file, 'w', newline = '')You’ll also notice, ( if you haven’t fallen asleep already) that I used the ‘csv.DictWriter’ (I’d love to know who comes up the naming in Python), as I am writing a list of Dictionaries to the CSV file. The DictWriter knows which dictionary fields to write to the CSV file using the “fieldnames=cols” attribute.
The CSV file looks something like this.
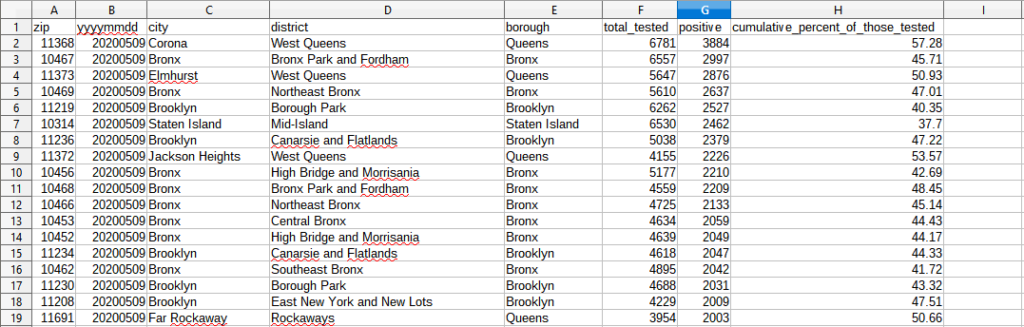
And that’s all I have to say about that.